Бывает такое, что страница исчезает из индекса поисковой системы. Это может случиться по множеству различных причин, вот некоторые из них:
- Страница запрещена к индексированию в Robots.txt
- Страница запрещена к индексированию в <meta name=«robots»>
- Страница в атрибуте canonical не соответствует URL страницы
- Страница имеет код ответа 30x (редирект), 40x (страница недоступна), 50x (ошибка сервера)
- Поисковая система выбрала другую страницу более релевантной
Все эти причины можно найти и проанализировать в сервисе Alfastat.
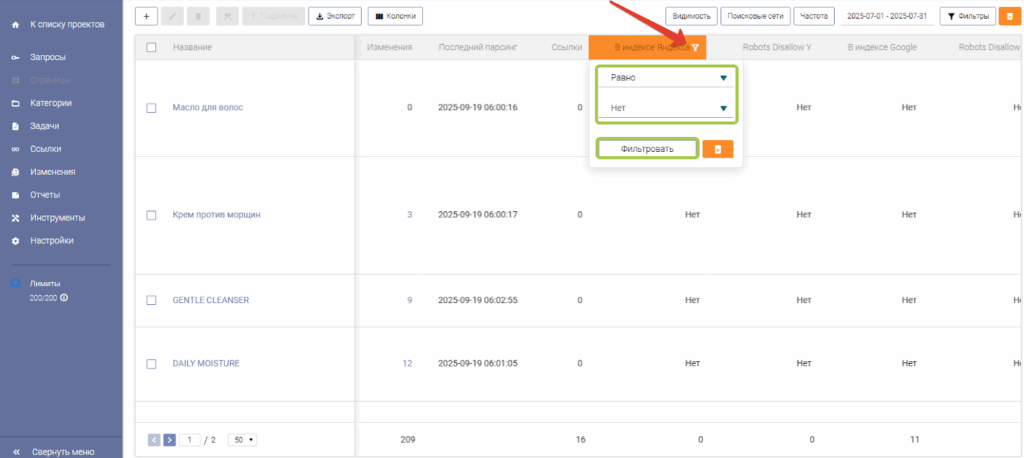
Прежде чем анализировать причины, необходимо обнаружить страницы, которые находятся не в индексе поисковой системы. Для этого необходимо отфильтровать колонку «В индексе Яндекса» или «В индексе Google» следующим образом:
- Нажать на иконку фильтрации возле названия колонки
- В выпадающем списке выбрать «Равно» и «Нет»
- Нажать кнопку «Фильтровать»
После этого в таблице будут отфильтрованы все страницы, которые на момент парсинга отсутствовали в индексе поисковой системы.
Страница запрещена к индексированию в Robots.txt #
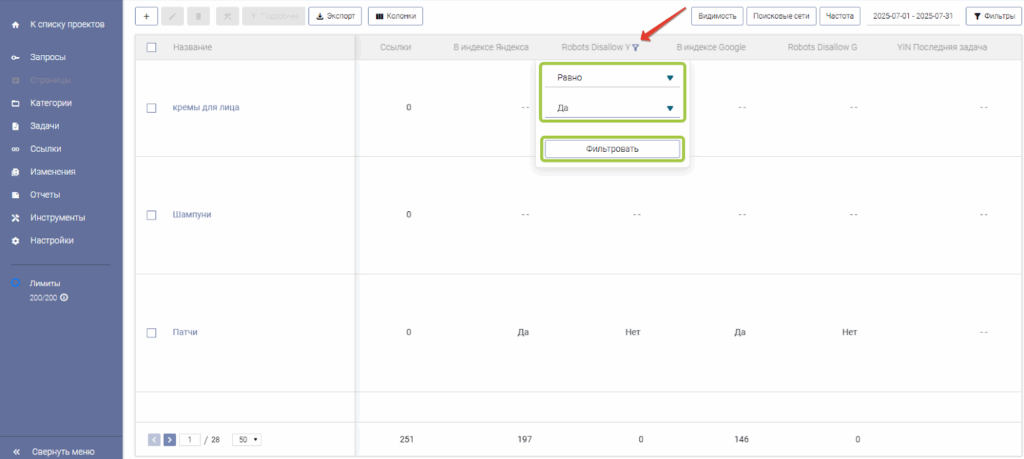
Для того чтобы найти страницы, которые запрещены к индексации в Robots.txt, необходимо отфильтровать колонки «Robots Disallow Y» и «Robots Disallow G».
Для этого:
- Нажать на иконку фильтрации возле названия колонки
- В выпадающем списке выбрать «Равно» и «Да»
- Нажать кнопку «Фильтровать»
После этого в таблице будут отфильтрованы все страницы, которые на момент парсинга были запрещены к индексации в Robots.txt в выбранной поисковой системе.
Страница запрещена к индексированию в <meta name=«robots»> #
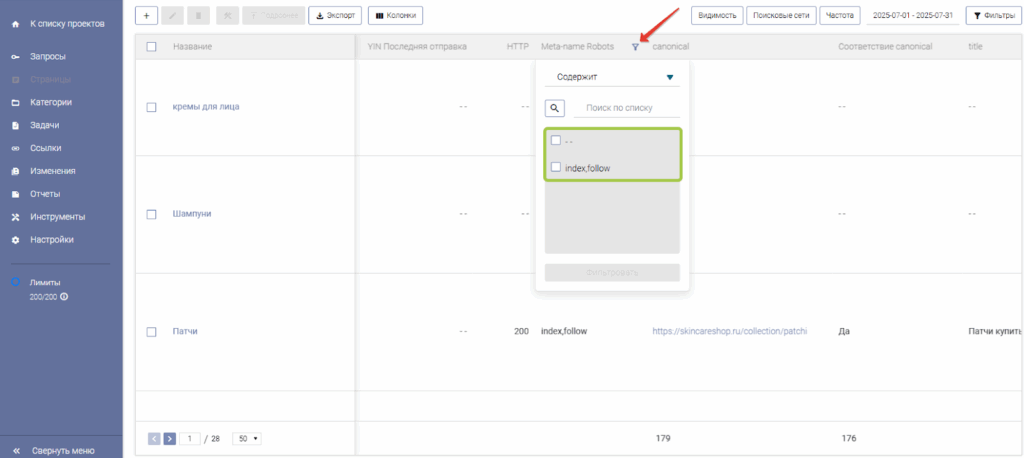
Для того чтобы проверить, есть ли страницы, запрещенные к индексации в <meta name=«robots»>, достаточно нажать на иконку фильтрации в колонке «Meta-name Robots» и посмотреть, какие значения есть в меню фильтрации. Если значений, связанных с запретом к индексации, в меню нет, то причина отсутствия страницы в индексе не в этом.
Какие могут быть значения:
«—» – URL страницы не указан либо <meta name=«robots»> отсутствует в коде страницы.
«index,follow» – страница доступна к индексации и посещению роботом.
«noindex,nofollow» – страница не доступна к индексации и посещению роботом.
Для того чтобы найти страницы, которые запрещены к индексации в <meta name=«robots»>, необходимо отфильтровать колонку «Meta-name Robots».
Для этого:
- Нажать на иконку фильтрации возле названия колонки
- В выпадающем списке выбрать значение «noindex,nofollow»
- Нажать кнопку «Фильтровать»
После этого в таблице будут отфильтрованы все страницы, которые на момент парсинга были запрещены к индексации в <meta name=«robots»>.
Страница в атрибуте canonical не соответствует URL страницы #
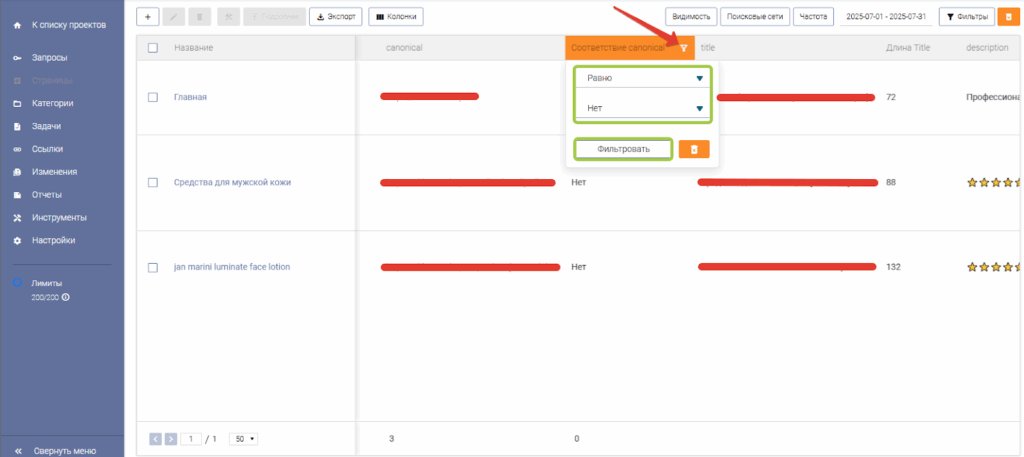
Для того чтобы найти страницы, у которых URL в атрибуте canonical не совпадает с URL страницы, необходимо отфильтровать колонку «Соответствие canonical».
Для этого:
- Нажать на иконку фильтрации возле названия колонки
- В выпадающем списке выбрать «Равно» и «Нет»
- Нажать кнопку «Фильтровать»
После этого в таблице будут отфильтрованы все страницы, у которых на момент парсинга URL в атрибуте canonical не совпадал с URL страницы.
Страница имеет код ответа 30x (редирект), 40x (страница недоступна), 50x (ошибка сервера) #
Для того чтобы проверить, есть ли страницы, запрещенные к индексации из-за некорректного кода ответа сервера, достаточно нажать на иконку фильтрации в колонке «HTTP» и посмотреть, какие значения есть в меню фильтрации. Если значений, связанных с запретом к индексации, в меню нет, то причина отсутствия страницы в индексе не в этом.
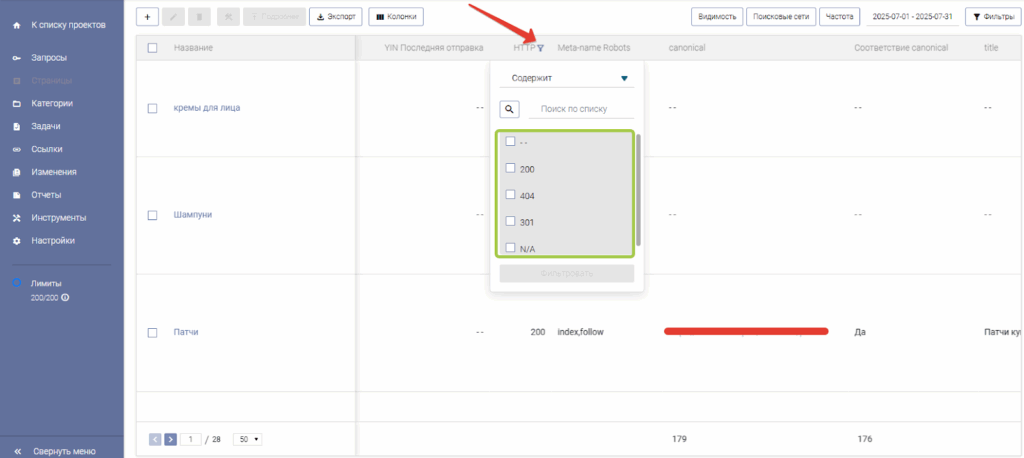
Какие могут быть значения:
Код ответа 200 – страница доступна.
Код ответа 30x – со страницы идет редирект на другую страницу.
Код ответа 40x – страница отсутствует или отдает другую ошибку.
Код ответа 50x – страница отсутствует или недоступна на уровне сервера.
Для того чтобы найти страницы, которые запрещены к индексации из-за некорректного кода ответа сервера, необходимо отфильтровать колонку «HTTP».
Для этого:
- Нажать на иконку фильтрации возле названия колонки
- В выпадающем списке выбрать некорректное значение кода ответа сервера
- Нажать кнопку «Фильтровать»
После этого в таблице будут отфильтрованы все страницы, которые на момент парсинга отдавали некорректное значение кода ответа сервера.
Поисковая система выбрала другую страницу более релевантной #
Если вы не обнаружили причин, перечисленных выше, по которым страница может быть закрыта от индексации, но страница все равно отсутствует в индексе, необходимо проверить, совпадает ли релевантный URL с текущим адресом страницы.
Для этого для каждого запроса в системе должен быть указан целевой URL. Как загрузить в систему целевые URL в связке с запросами, описано в статье «Добавление запросов».
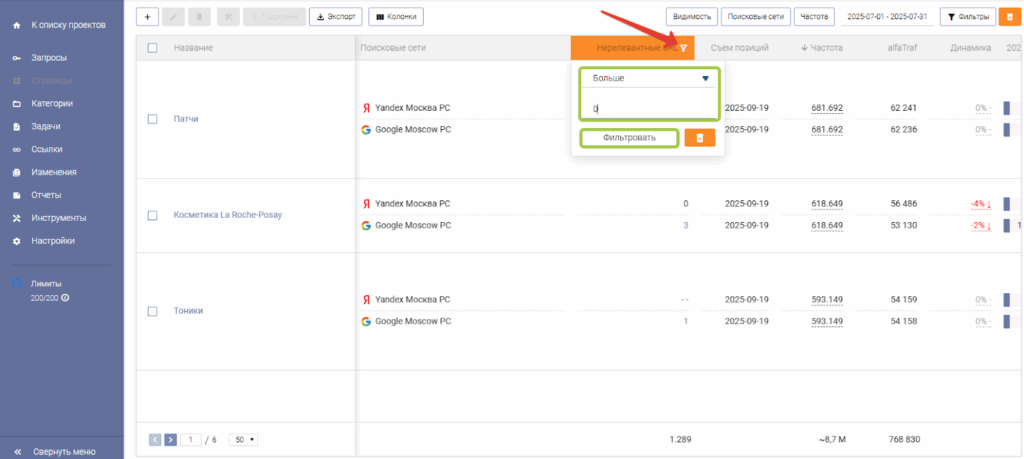
Если вы добавили к каждому запросу целевой URL, то для того чтобы найти нерелевантные URL, на экране «Страницы» необходимо отфильтровать колонку «Нерелевантные URL».
Для этого:
- Нажать на иконку фильтрации возле названия колонки
- В выпадающем списке выбрать «Больше» и «0»
- Нажать кнопку «Фильтровать»
После этого в таблице будут отфильтрованы все страницы, у которых на момент съема позиций по запросам, относящимся к данной странице, были обнаружены нерелевантные URL (то есть URL, несоответствующие целевой странице, которую вы указали при внесении запросов в сервис).
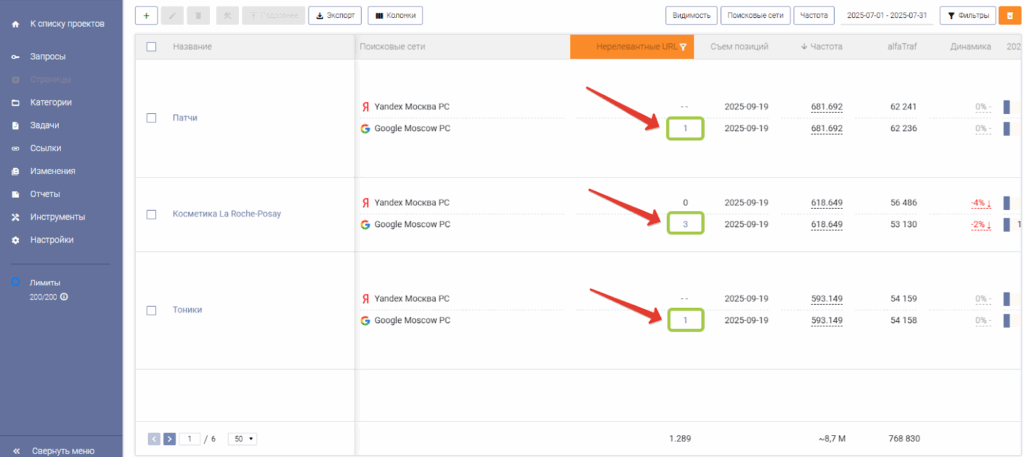
В колонке отобразится количество нерелевантных URL для каждой страницы по каждой поисковой системе. Для того чтобы проверить, какие запросы не совпадают с целевым URL в поисковой системе, нажмите на значение в колонке.
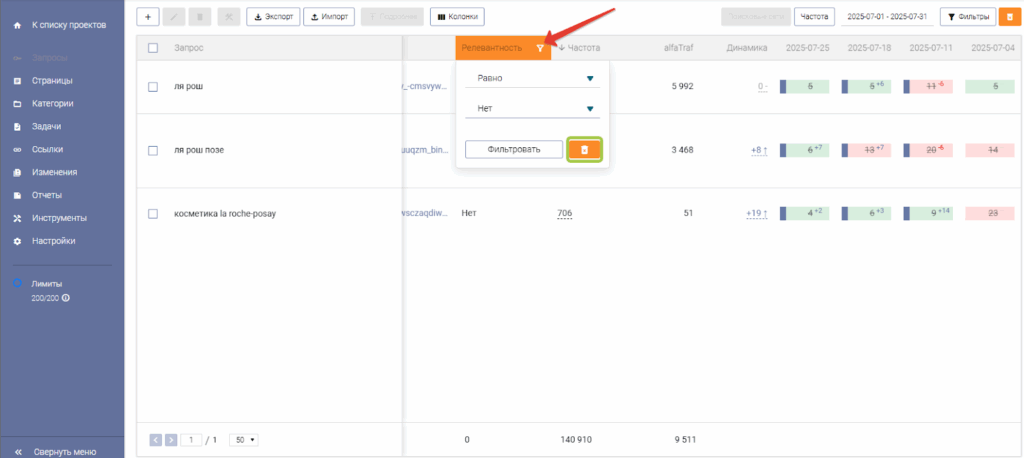
После этого вы попадете на экран «Запросы», где будут применены фильтры по колонкам «ID страницы», «Поисковые сети» и «Релевантность».
Для того чтобы определить, является ли отсутствие релевантных запросов в поисковой выдаче косвенной причиной отсутствия целевой страницы в индексе, удалите фильтр с колонки «Релевантность».
Для этого необходимо:
- Нажать на иконку фильтрации возле названия колонки
- Нажать кнопку «Удалить»
Далее проанализируйте, какие страницы находятся в поисковой выдаче по всем запросам из кластера. Если все запросы из кластера ведут на другие страницы, а не на целевой URL, это может говорить о нескольких причинах, почему поисковая система удалила страницу из индекса:
- Поисковая система могла признать целевой URL нерелевантным данному кластеру запросов.
- На страницу отсутствует доступ с сайта (нет внутренней перелинковки).
- Отсутствует внутренняя оптимизация.
- Поисковая система признала страницу малополезным контентом.
- На страницу отсутствуют внешние ссылки.